
回溯就是递归遍历一颗多叉树,答案就在路径上,有时候需要对树进行剪枝。
使用回溯时,记录路径的变量必须要保持一致性的状态,有做选择就有撤销选择,必须一一对应。
# 一些经典的题目
# 46. 全排列 (opens new window)
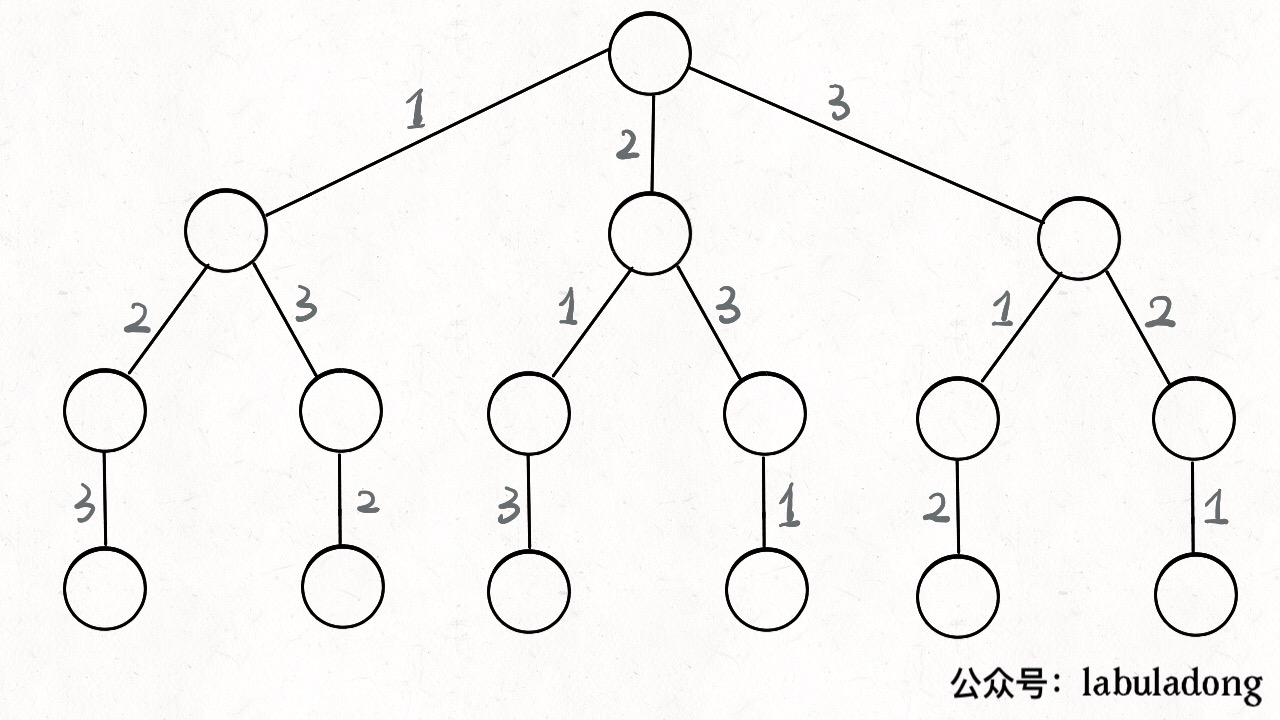
对于[1,2,3]这样一个数组,我们要生成它的全排列,我们可以画出它的决策树,每次选择就是向下搜索的过程。
class Solution {
public List<List<Integer>> permute(int[] nums) {
List<List<Integer>> ans = new ArrayList<>();
dfs(ans, new ArrayList<>(), nums, new boolean[nums.length]);
return ans;
}
public void dfs(List<List<Integer>> ans, List<Integer> list, int[] nums, boolean[] visited){
if(list.size() == nums.length){
// 当已经选择了所有的数,将list放入ans列表,注意要用创建新的对象保存list
// 否者list会因为回溯而变为空列表
ans.add(new ArrayList<>(list));
return ;
}
for(int i = 0; i < nums.length; i++){
if(visited[i] == true)
continue;
visited[i] = true;
list.add(nums[i]);
dfs(ans, list, nums, visited);
list.remove(list.size() - 1); // 回溯
visited[i] = false; // 回溯
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 47. 全排列 II (opens new window)
与上一题所不同的是,数组中可能包含重复的值,因此,会产生重复的答案,这时候我们需要进行剪枝去掉重复。
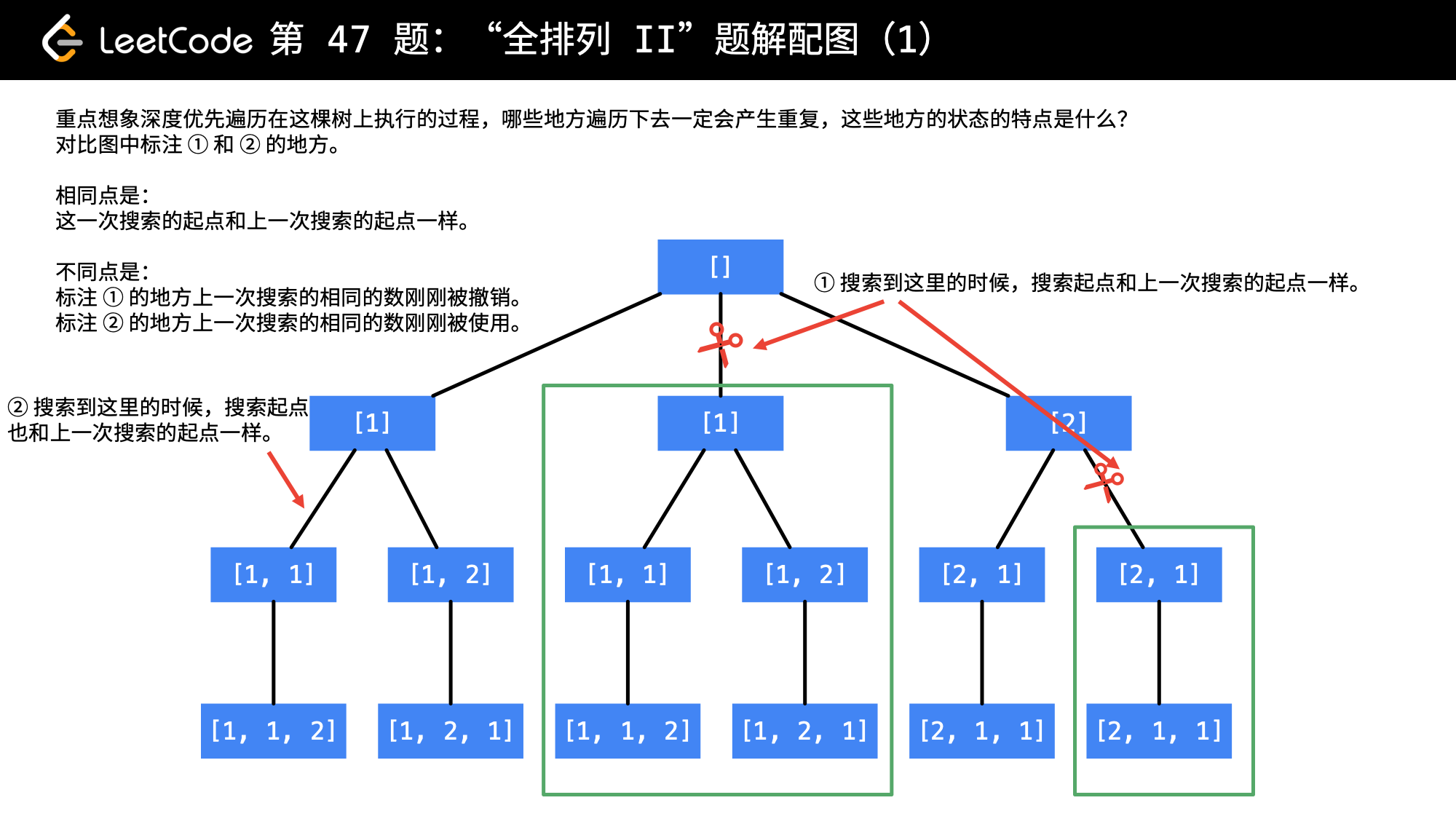 图片来源
图片来源
class Solution {
public List<List<Integer>> permuteUnique(int[] nums) {
Arrays.sort(nums);
List<List<Integer>> ans = new ArrayList<>();
dfs(ans, new ArrayList<>(), nums, new boolean[nums.length]);
return ans;
}
public void dfs(List<List<Integer>> ans, List<Integer> list, int[] nums, boolean[] visited){
if(list.size() == nums.length){
ans.add(new ArrayList<>(list));
return ;
}
for(int i = 0; i < nums.length; i++){
if(visited[i] == true)
continue;
visited[i] = true;
list.add(nums[i]);
dfs(ans, list, nums, visited);
list.remove(list.size() - 1);
visited[i] = false;
// 我们要剪掉一个重复的枝,两个重复的枝在同一层,因此在回溯之后跳过相同的根
while(i+1 < nums.length && nums[i] == nums[i+1])
i++;
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 40. 组合总和 II (opens new window)
与排列所不同的是,组合不用考虑元素的顺序,即拥有相同元素的集合但排列不同可以认定为同一个答案。
class Solution {
public List<List<Integer>> combinationSum2(int[] candidates, int target) {
List<List<Integer>> ans = new ArrayList<>();
// 排序,使得相同的元素处在一块,以便剪枝
Arrays.sort(candidates);
dfs(ans, new ArrayList<Integer>(),candidates, target, 0);
return ans;
}
public void dfs(List<List<Integer>> ans, List<Integer> list, int[] candidates, int target, int j){
// 递归出口,不加该条件会一直递归下去
if(target <= 0){
if(target == 0)
ans.add(new ArrayList<>(list));
return ;
}
for(int i = j; i < candidates.length; i++){
list.add(candidates[i]);
// 参数中i+1表明了同一个元素只能使用一次,下次递归选择余下的元素
dfs(ans, list, candidates, target - candidates[i], i+1);
list.remove(list.size()-1);
// 剪枝
while(i+1 < candidates.length && candidates[i] == candidates[i+1])
i++;
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 90. 子集 II (opens new window)
与排列和组合不同的是,答案在当前节点到根节点的路径上,而不是叶子节点到根节点的路径。
画出决策树,两个产生重复的答案子集会在树的同一层,因此在后续遍历时跳过相同的元素。
class Solution {
public List<List<Integer>> subsetsWithDup(int[] nums) {
List<List<Integer>> ans = new ArrayList<>();
// 排序使相同的元素处在一块,便于剪枝
Arrays.sort(nums);
dfs(ans, new ArrayList<>(), nums, 0);
return ans;
}
public void dfs(List<List<Integer>> ans, List<Integer> list, int[] nums, int i){
ans.add(new ArrayList<>(list));
for(int j = i; j < nums.length; j++){
list.add(nums[j]);
dfs(ans, list, nums, j+1);
list.remove(list.size() - 1);
while(j + 1 < nums.length && nums[j] == nums[j+1])
j++;
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 236. 二叉树的最近公共祖先 (opens new window)
通过回溯得到从根到p,q两个节点的路径,然后遍历这两个路径,找到最右的相同节点即为最近公共祖先,注意回溯时维护的状态(即下面代码中的path列表)即要有压栈也要有出栈的过程。
class Solution {
List<TreeNode> pathTop = new ArrayList<>();
List<TreeNode> pathToq = new ArrayList<>();
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if(root == null)
return null;
dfs(root, p, q, new ArrayList<>());
int i = 0;
while(i < pathTop.size() && i < pathToq.size() && pathTop.get(i) == pathToq.get(i))
i++;
return pathToq.get(i-1) ;
}
public void dfs(TreeNode root, TreeNode p, TreeNode q, List<TreeNode> path){
if(root == null){
return;
}
path.add(root); // 压栈
if(root == p){
pathTop.addAll(path); // 注意不能在这里加return,否则无法正确回溯
}
if(root == q){
pathToq.addAll(path);
}
dfs(root.left, p, q, path);
dfs(root.right, p, q, path);
path.remove(path.size() - 1); // 出栈
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
更妙的方法
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if(root == null)
return null;
if(root == p || root == q)
return root;
TreeNode left = lowestCommonAncestor(root.left, p, q);
TreeNode right = lowestCommonAncestor(root.right, p, q);
// 如果在root的左右子树中都找到p、q了,那么此时的p、q分别在root的左右子树中,此时p、q的祖先就是root
if(left != null && right != null)
return root;
// 只找到其中一个,说明可能p、q同在root的左子树或者右子树中,也可能在别的子树中
if(left != null)
return left;
if(right != null)
return right;
// 以root为根的子树中没有找到p、q,没有公共祖先,返回null
return null;
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 模板
LinkedList result = new LinkedList();
public void backtrack(路径,选择列表){
if(满足结束条件){
result.add(结果);
}
for(选择:选择列表){
做出选择;
backtrack(路径,选择列表);
撤销选择;
}
}
1
2
3
4
5
6
7
8
9
10
11
2
3
4
5
6
7
8
9
10
11